Building a Data Platform: Overcoming the Challenges
Building a Data Platform: Overcoming the Challenges
Building a Data Platform: Overcoming the Challenges
Learn what it takes to build a system that is reliable, efficient, and scalable.
Learn what it takes to build a system that is reliable, efficient, and scalable.
Learn what it takes to build a system that is reliable, efficient, and scalable.

Toplyne helps businesses improve their win rates and reduce their sales cycle. We do this by identifying leads that are most likely to convert.
Our customers can choose to ingest data from various sources, such as analytics tools, CRM systems, S3 storage, and data warehouses (such as Snowflake and BigQuery). Based on the input provided by our customers, we generate code for data transformation dynamically and make the data available to our data science team in a more consumable format.
The data science team uses this data to automatically generate models, create cohorts, and score leads. This data is then made available to them on a dashboard and fed back to their GTM and CRM tools using reverse ETL (extract, transform, load).
All of this — with 0 manual intervention.
One of the key pieces that enables this is the multi-tenant data platform we have built. We have created a stack that scales seamlessly, is reliable, and can be extended for different use cases while minimizing our overall cost.
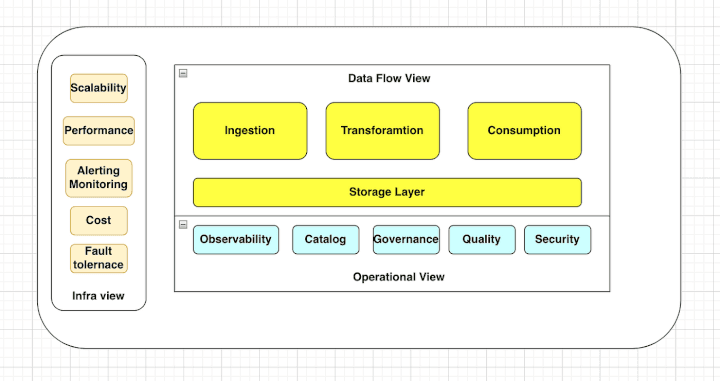
A data platform can have multiple dimensions, and each view (data flow, operational, and infra) has its own set of problems to be solved. It is important to consider all of these views and the problems they represent when building a data platform, in order to create a system that is reliable, efficient, and scalable. In this blog, we will focus on these three views and the problems we need to solve across each view.
Different Views in a Data Platform
Data Flow View: This view is helpful in visualizing how data flows through each step of your process. It helps you understand the dependencies and relationships between different data sources, transformations, and outputs.
Operational View: The operational view shows you the actual data from your system, including any errors or issues. It is concerned with the day-to-day management and operation of the platform.
Infra View: The infra view shows you all the infrastructure and processes that make up your system. It helps you understand how different parts of the system work together as a whole and allows you to optimize resources and performance.
Data Flow View
The data flow view of a data platform is concerned with the flow of data through the platform, from ingestion to storage to consumption. We will explore the different layers of the data flow view and the problems that need to be solved in each layer of the data flow.
Ingestion Layer
Transformation Layer
Orchestration Layer
Storage Layer
Consumption Layer
Ingestion layer
An ingestion pipeline is a set of processes and technologies that enable organizations to efficiently and securely import data into their data platform. When a customer is onboarded to a data platform, there are several key issues that need to be addressed when setting up the ingestion pipeline. These include:
Handling schema evolution: As data sources change over time, the structure of the data may also change. The data ingestion layer should be able to handle these changes and adjust the data schema as needed.
Code Extensibility: How should the ingestion code be structured to allow for easy maintenance and extension for new sources?
Data integration: Data from different sources may be in different formats, structures, or schemas, and it needs to be integrated and transformed into a consistent format.
Providing authentication for data sources: To ensure security and compliance, the data ingestion layer should have mechanisms in place to authenticate data sources before allowing them to access the data.
Data security: Data may contain sensitive or confidential information, and it needs to be protected and secured during ingestion.
Converting raw data into a usable format: In order to ingest data, it must be in a format that is compatible with the data platform.
Dealing with unstructured data: Some data sources, may not have a fixed structure. This can make it difficult to process and analyze the data and may require using tools like SQL or NoSQL databases to create a structure for the data.
Managing synchronization frequency: It is important to determine how often data should be ingested from different sources and to have mechanisms in place to control the ingestion speed if needed.
Supporting real-time data ingestion: In some cases, it may be necessary to ingest data in real-time, as it is generated. This can be challenging and may require the use of streaming platforms or other technologies.
Batching: Should data be ingested in small batches or large ones? What is the optimal batch size for the system?
Ingesting data from multiple cloud regions: To ensure flexibility and scalability, the data ingestion layer should be able to ingest data from any cloud in any region.
Transformation Layer
The data transformation process is a critical part of the modern data stack, as it involves transforming data from multiple sources into a consistent format and enriching it with additional information or context. Some key problems that need to be solved in this process include:
Transforming data from multiple sources into a consistent format: This involves extracting data from various sources and converting it into a format that is usable and consistent across the system.
Enriching data with additional information or context: This involves adding additional data or context to the data set, in order to make it more valuable and useful.
Cleaning and validating data to ensure accuracy and completeness: This involves removing errors or inconsistencies from the data set, and ensuring that it is complete and accurate.
De-duplicating data to remove duplicate or redundant entries: This involves identifying and removing duplicate or redundant data from the data set, in order to avoid confusion or inconsistencies.
Implementing data governance and security measures: This involves putting policies and procedures in place to ensure the security, compliance, and integrity of the data.
Providing a way to track and audit data transformation processes: This involves creating a system for tracking and auditing the data transformation process, in order to ensure accountability and transparency.
Supporting data transformation at scale: This involves building a system that can handle large volumes of data and transformations, in order to support the needs of the organization.
Handling errors and exceptions in the transformation process: This involves creating a system for handling and recovering from errors or exceptions that may occur during the transformation process.
Providing a clear interface for users to monitor and manage data transformation: This involves creating an interface or dashboard that allows users to monitor and manage the data transformation process
Orchestration Layer
The orchestration layer is responsible for coordinating and scheduling the processing of data. Some of the problems that need to be solved in the orchestration layer include:
Workflow management: Data processing often involves multiple tasks and dependencies, and the orchestration layer needs to manage and execute these tasks in the correct order.
Resource management: Data processing may require different types of resources, such as computing, storage, and networking, and the orchestration layer needs to allocate and optimize these resources.
Monitoring and alerting: The orchestration layer needs to monitor the progress and status of data processing tasks and alert stakeholders if there are any issues or failures.
Storage Layer
The storage layer of a data platform is responsible for storing data in a persistent and accessible way. Some key problems to solve in the storage layer include:
Data modeling: How should the data be structured and organized to support the needs of the organization?
Data partitioning: How should the data be partitioned to improve performance and scalability?
Data compression: How should the data be compressed to save space and improve performance?
Data indexing: How should the data be indexed to support fast querying and filtering?
Data security: How should the data be protected from unauthorized access or tampering?
Data backup and recovery: How should the data be backed up and recovered in case of failures or disasters?
Query access pattern and SLA (service-level agreement) for read and write: This involves determining the expected access patterns for data queries, and setting appropriate SLAs for performance and availability.
Data consistency: This involves ensuring that data is consistent across the system and that updates and changes are propagated in a timely and accurate manner.
Transaction requirements, data mutation, streaming support, and schema evolution: These factors all influence the design and implementation of the storage layer, and should be carefully considered in order to ensure the reliability and flexibility of the system.
Query performance: This involves optimizing the performance of data queries, in order to provide fast and reliable access to data.
Segmentation: This involves dividing data into segments or partitions, in order to improve performance and scalability.
Capturing metadata: This involves collecting and storing metadata about the data, such as its structure, lineage, and provenance.
Data archival: This involves developing a strategy for archiving data that is no longer needed or used, in order to save space and improve performance.
Consumption Layer
The consumption layer of a data platform is responsible for making data available to users and applications. Some key problems to solve in the consumption layer include:
Reverse ETL (Extract, Transform, Load): This involves creating a process for rolling back or undoing data transformations, in order to correct errors or revert to previous versions.
Data visualization/Reporting: Presenting the data in a way that is easy to understand and consume by end-users, such as analysts, business intelligence teams, and data scientists.
Machine Learning: Access and manipulate data for predictive analysis, data visualization, and decision-making.
Operational View
The operational view of a data platform is concerned with the day-to-day management and operation of the platform. It consists of several key areas, including data observability, data catalog, data quality, and data governance. Some of the problems that need to be solved in these areas include:
Data observability: This involves ensuring that data is available, accurate, and trustworthy and that any issues or errors are quickly identified and addressed.
Data catalog: This involves storing, organizing, and documenting data in a way that makes it easy to find and access.
Data quality: This involves ensuring that data is accurate and complete and that it meets the expectations of users and the business.
Data governance: This involves establishing policies and procedures to ensure that data is used appropriately and responsibly and that everyone involved in a project has the right level of access and understanding of their roles and responsibilities.
Compliance: This involves ensuring that the data platform adheres to relevant laws, regulations, and standards.
RBAC (role-based access control): This involves implementing a system for controlling access to data based on the roles and permissions of users.
Security — To ensure that access rights are appropriately applied to each version of the database, we need to ensure that all users have appropriate privileges and roles in the system.
Solving these problems in the operational view is key to ensuring that the data platform runs smoothly and effectively.
Infra View
The infra view of a data platform is concerned with the underlying infrastructure and architecture of the platform. Some key considerations in this view include:
Scalability: The data platform should be able to scale up or down as needed to meet changing demands.
Performance: The data platform should be able to handle high volumes of data and queries with low latency.
Manageability: The data platform should be easy to maintain and upgrade, with clear documentation and processes in place.
Cost: The data platform should be cost-effective, with a balance between performance and price.
Fault tolerance: The data platform should be able to withstand failures and outages, with redundant systems and backup procedures in place.
Multi-tenant setup: If the data platform will be used by multiple tenants or users, it should be able to support a multi-tenant setup with appropriate isolation and security measures.
Infrastructure: The data platform should be built on robust and reliable infrastructure, such as servers, storage, and networking.
Alerting and monitoring: The data platform should have robust alerting and monitoring systems in place to detect and respond to issues and failures.
Latency: The data platform should have low latency, meaning the time it takes for data to be processed and made available for use.
Throughput: The data platform should have high throughput, meaning the amount of data that can be processed and stored over a given period of time.
It is important to prioritize the infra view of their data platform to ensure that it is reliable, secure, and capable of meeting the demands of their business.
In conclusion, building a data platform is complex and requires addressing multiple dimensions, including the data flow, operational, and infra views. Each of these views has its own set of problems to solve, ranging from data ingestion to storage, transformation, consumption, and management.
Solving these problems requires a deep understanding of the needs of the organization, as well as the tools, technologies, and processes required to support them.
At Toplyne, we have built a multi-tenant data platform that scales seamlessly, is reliable, and can be extended for different use cases, while minimizing our overall cost.
We hope that this blog provides a useful overview of the different views of a data platform and the problems that need to be solved in each view.
Toplyne helps businesses improve their win rates and reduce their sales cycle. We do this by identifying leads that are most likely to convert.
Our customers can choose to ingest data from various sources, such as analytics tools, CRM systems, S3 storage, and data warehouses (such as Snowflake and BigQuery). Based on the input provided by our customers, we generate code for data transformation dynamically and make the data available to our data science team in a more consumable format.
The data science team uses this data to automatically generate models, create cohorts, and score leads. This data is then made available to them on a dashboard and fed back to their GTM and CRM tools using reverse ETL (extract, transform, load).
All of this — with 0 manual intervention.
One of the key pieces that enables this is the multi-tenant data platform we have built. We have created a stack that scales seamlessly, is reliable, and can be extended for different use cases while minimizing our overall cost.
A data platform can have multiple dimensions, and each view (data flow, operational, and infra) has its own set of problems to be solved. It is important to consider all of these views and the problems they represent when building a data platform, in order to create a system that is reliable, efficient, and scalable. In this blog, we will focus on these three views and the problems we need to solve across each view.
Different Views in a Data Platform
Data Flow View: This view is helpful in visualizing how data flows through each step of your process. It helps you understand the dependencies and relationships between different data sources, transformations, and outputs.
Operational View: The operational view shows you the actual data from your system, including any errors or issues. It is concerned with the day-to-day management and operation of the platform.
Infra View: The infra view shows you all the infrastructure and processes that make up your system. It helps you understand how different parts of the system work together as a whole and allows you to optimize resources and performance.
Data Flow View
The data flow view of a data platform is concerned with the flow of data through the platform, from ingestion to storage to consumption. We will explore the different layers of the data flow view and the problems that need to be solved in each layer of the data flow.
Ingestion Layer
Transformation Layer
Orchestration Layer
Storage Layer
Consumption Layer
Ingestion layer
An ingestion pipeline is a set of processes and technologies that enable organizations to efficiently and securely import data into their data platform. When a customer is onboarded to a data platform, there are several key issues that need to be addressed when setting up the ingestion pipeline. These include:
Handling schema evolution: As data sources change over time, the structure of the data may also change. The data ingestion layer should be able to handle these changes and adjust the data schema as needed.
Code Extensibility: How should the ingestion code be structured to allow for easy maintenance and extension for new sources?
Data integration: Data from different sources may be in different formats, structures, or schemas, and it needs to be integrated and transformed into a consistent format.
Providing authentication for data sources: To ensure security and compliance, the data ingestion layer should have mechanisms in place to authenticate data sources before allowing them to access the data.
Data security: Data may contain sensitive or confidential information, and it needs to be protected and secured during ingestion.
Converting raw data into a usable format: In order to ingest data, it must be in a format that is compatible with the data platform.
Dealing with unstructured data: Some data sources, may not have a fixed structure. This can make it difficult to process and analyze the data and may require using tools like SQL or NoSQL databases to create a structure for the data.
Managing synchronization frequency: It is important to determine how often data should be ingested from different sources and to have mechanisms in place to control the ingestion speed if needed.
Supporting real-time data ingestion: In some cases, it may be necessary to ingest data in real-time, as it is generated. This can be challenging and may require the use of streaming platforms or other technologies.
Batching: Should data be ingested in small batches or large ones? What is the optimal batch size for the system?
Ingesting data from multiple cloud regions: To ensure flexibility and scalability, the data ingestion layer should be able to ingest data from any cloud in any region.
Transformation Layer
The data transformation process is a critical part of the modern data stack, as it involves transforming data from multiple sources into a consistent format and enriching it with additional information or context. Some key problems that need to be solved in this process include:
Transforming data from multiple sources into a consistent format: This involves extracting data from various sources and converting it into a format that is usable and consistent across the system.
Enriching data with additional information or context: This involves adding additional data or context to the data set, in order to make it more valuable and useful.
Cleaning and validating data to ensure accuracy and completeness: This involves removing errors or inconsistencies from the data set, and ensuring that it is complete and accurate.
De-duplicating data to remove duplicate or redundant entries: This involves identifying and removing duplicate or redundant data from the data set, in order to avoid confusion or inconsistencies.
Implementing data governance and security measures: This involves putting policies and procedures in place to ensure the security, compliance, and integrity of the data.
Providing a way to track and audit data transformation processes: This involves creating a system for tracking and auditing the data transformation process, in order to ensure accountability and transparency.
Supporting data transformation at scale: This involves building a system that can handle large volumes of data and transformations, in order to support the needs of the organization.
Handling errors and exceptions in the transformation process: This involves creating a system for handling and recovering from errors or exceptions that may occur during the transformation process.
Providing a clear interface for users to monitor and manage data transformation: This involves creating an interface or dashboard that allows users to monitor and manage the data transformation process
Orchestration Layer
The orchestration layer is responsible for coordinating and scheduling the processing of data. Some of the problems that need to be solved in the orchestration layer include:
Workflow management: Data processing often involves multiple tasks and dependencies, and the orchestration layer needs to manage and execute these tasks in the correct order.
Resource management: Data processing may require different types of resources, such as computing, storage, and networking, and the orchestration layer needs to allocate and optimize these resources.
Monitoring and alerting: The orchestration layer needs to monitor the progress and status of data processing tasks and alert stakeholders if there are any issues or failures.
Storage Layer
The storage layer of a data platform is responsible for storing data in a persistent and accessible way. Some key problems to solve in the storage layer include:
Data modeling: How should the data be structured and organized to support the needs of the organization?
Data partitioning: How should the data be partitioned to improve performance and scalability?
Data compression: How should the data be compressed to save space and improve performance?
Data indexing: How should the data be indexed to support fast querying and filtering?
Data security: How should the data be protected from unauthorized access or tampering?
Data backup and recovery: How should the data be backed up and recovered in case of failures or disasters?
Query access pattern and SLA (service-level agreement) for read and write: This involves determining the expected access patterns for data queries, and setting appropriate SLAs for performance and availability.
Data consistency: This involves ensuring that data is consistent across the system and that updates and changes are propagated in a timely and accurate manner.
Transaction requirements, data mutation, streaming support, and schema evolution: These factors all influence the design and implementation of the storage layer, and should be carefully considered in order to ensure the reliability and flexibility of the system.
Query performance: This involves optimizing the performance of data queries, in order to provide fast and reliable access to data.
Segmentation: This involves dividing data into segments or partitions, in order to improve performance and scalability.
Capturing metadata: This involves collecting and storing metadata about the data, such as its structure, lineage, and provenance.
Data archival: This involves developing a strategy for archiving data that is no longer needed or used, in order to save space and improve performance.
Consumption Layer
The consumption layer of a data platform is responsible for making data available to users and applications. Some key problems to solve in the consumption layer include:
Reverse ETL (Extract, Transform, Load): This involves creating a process for rolling back or undoing data transformations, in order to correct errors or revert to previous versions.
Data visualization/Reporting: Presenting the data in a way that is easy to understand and consume by end-users, such as analysts, business intelligence teams, and data scientists.
Machine Learning: Access and manipulate data for predictive analysis, data visualization, and decision-making.
Operational View
The operational view of a data platform is concerned with the day-to-day management and operation of the platform. It consists of several key areas, including data observability, data catalog, data quality, and data governance. Some of the problems that need to be solved in these areas include:
Data observability: This involves ensuring that data is available, accurate, and trustworthy and that any issues or errors are quickly identified and addressed.
Data catalog: This involves storing, organizing, and documenting data in a way that makes it easy to find and access.
Data quality: This involves ensuring that data is accurate and complete and that it meets the expectations of users and the business.
Data governance: This involves establishing policies and procedures to ensure that data is used appropriately and responsibly and that everyone involved in a project has the right level of access and understanding of their roles and responsibilities.
Compliance: This involves ensuring that the data platform adheres to relevant laws, regulations, and standards.
RBAC (role-based access control): This involves implementing a system for controlling access to data based on the roles and permissions of users.
Security — To ensure that access rights are appropriately applied to each version of the database, we need to ensure that all users have appropriate privileges and roles in the system.
Solving these problems in the operational view is key to ensuring that the data platform runs smoothly and effectively.
Infra View
The infra view of a data platform is concerned with the underlying infrastructure and architecture of the platform. Some key considerations in this view include:
Scalability: The data platform should be able to scale up or down as needed to meet changing demands.
Performance: The data platform should be able to handle high volumes of data and queries with low latency.
Manageability: The data platform should be easy to maintain and upgrade, with clear documentation and processes in place.
Cost: The data platform should be cost-effective, with a balance between performance and price.
Fault tolerance: The data platform should be able to withstand failures and outages, with redundant systems and backup procedures in place.
Multi-tenant setup: If the data platform will be used by multiple tenants or users, it should be able to support a multi-tenant setup with appropriate isolation and security measures.
Infrastructure: The data platform should be built on robust and reliable infrastructure, such as servers, storage, and networking.
Alerting and monitoring: The data platform should have robust alerting and monitoring systems in place to detect and respond to issues and failures.
Latency: The data platform should have low latency, meaning the time it takes for data to be processed and made available for use.
Throughput: The data platform should have high throughput, meaning the amount of data that can be processed and stored over a given period of time.
It is important to prioritize the infra view of their data platform to ensure that it is reliable, secure, and capable of meeting the demands of their business.
In conclusion, building a data platform is complex and requires addressing multiple dimensions, including the data flow, operational, and infra views. Each of these views has its own set of problems to solve, ranging from data ingestion to storage, transformation, consumption, and management.
Solving these problems requires a deep understanding of the needs of the organization, as well as the tools, technologies, and processes required to support them.
At Toplyne, we have built a multi-tenant data platform that scales seamlessly, is reliable, and can be extended for different use cases, while minimizing our overall cost.
We hope that this blog provides a useful overview of the different views of a data platform and the problems that need to be solved in each view.
Related Articles

Behavioral Retargeting: A Game-Changer in the Cookieless Era
Unlock the power of behavioral retargeting for the cookieless future! Learn how it personalizes ads & boosts conversions. #behavioralretargeting

All of Toplyne's 40+ Badges in the G2 Spring Reports
Our customers awarded us 40+ badges in G2's Summer Report 2024.

Unlocking the Full Potential of Google PMax Campaigns: Mastering Audience Selection to Double Your ROAS
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024